In 1893, Lucius A. Sherman counted sentence lengths of novels, noting that literary language appears to become simpler over time, aligning itself to a more direct oral style in Sherman’s time. Though Sherman’s book represents a limited study of select (canonic) fiction, the inquiry into the “evolution of literary language” remains captivating, especially as we devise methods to approach a solution (for one, we don’t have to count words by hand). Recently, computational literary studies has taken up the long term diachronic study of literary texts, leveraging the conceptual framework of literary studies and the tools and methods of humanities computing (Underwood 2019; Moretti, 2000). For example, one study suggests that, over time, literary texts have come to have a higher density of information, a development not found in, for example, parliamentary transcripts (Liddle, 2019). Following this inquiry into the diachronic development of literary style, we set ourselves the task of probing the change in stylistic and narrative features related to text complexity over time in a large corpus of novels (1880-2000), a study we presented at NLP4DH in Tokyo.
We found that some features remain the same over time, like text compressibility or lexical richness, as well as measures that indicate the complexity of novels at the level of their sentiment arc (for more on these measures, see our introductory blogpost on the topic). Yet some also appear to change significantly, showing a correlation (slope) as we study them over time. Sentence length, for example, as Sherman suggested, appears to decrease. The strongest correlation with time, however, we found to be for readability, that is, metrics that estimate the reading ease of text using various measures of word, syllable and sentence length as well as vocabulary simplicity.
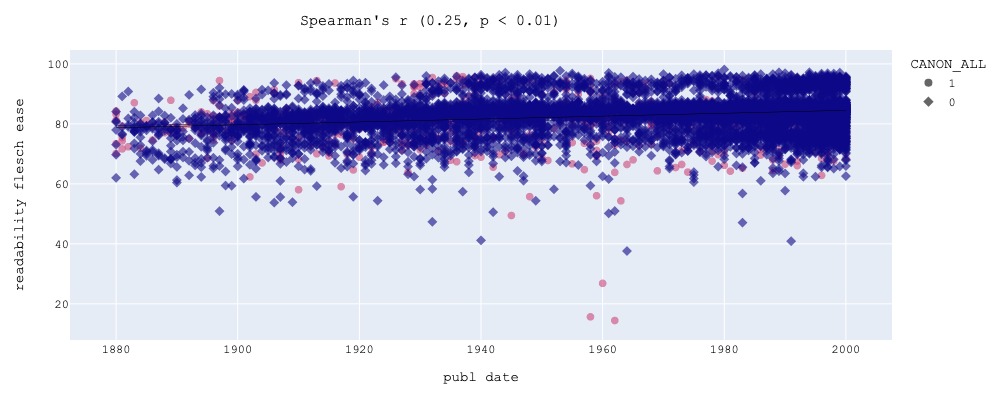
Even if these readability indices are a relatively simplistic measure of text complexity, it is widely accepted that simple textual features such as sentence length, syllables per word and lexical diversity do impact reading experience. In the context of literary prose, readability metrics are not only highly employed today (such as in writing tools like the Hemingway or Marlowe editors), we also appear to be able to use them to tell different forms of reader appreciation apart: while users on GoodReads appear to value more readable books, books that win prestigious awards appear less readable (Bizzoni, 2023). For more on the applicability of readability metrics on literary prose, see our blogpost on the topic (we did some experiments).
Are canonic, or “difficult” books also becoming easier?
Because we wanted to know whether this trend is stable across different types of fiction, we divided our corpus into canonic and noncanonic fiction, using various proxies of literary excellence to decide what are “canonic” works (for example, if an author is mentioned in the Norton Anthology). And indeed, the same features stay the same and change in the canonic subset of titles.
Losing complexity – or striking a balance?
The clear trend of all readability measures indicates an overall simplification of the literary prose. However, it is not irrelevant that we do not see a tendency towards simpler arcs through time: if books become easier to read from 1880 to 2000, they do not become simpler in terms of their sentiment-arc dynamics. The overall level of complexity of the novels’ sentiment arcs remains remarkably stable through the corpus - and the titles of our “canon selection” even show a slight tendency towards higher complexity through time. With time, writers might have increasingly favored a kind of prose that strives to keep a non-obvious balance between simplicity of style and complexity of their narrative arc, at least as far as it is measured by the large-scale dynamics of their sentiment trendline. The lack of lasting diachronic changes in the other two stylistic measures considered, type-token ratio and textual compressibility, seems to confirm this picture: if novels become easier in terms of basic readability metrics, they do not lose complexity at many other levels, not becoming overall more repetitive nor lexically poorer. In other words, it might be that there has been a large, overall tendency to favor texts that manage to simplify the most surface level aspect of style, without compromising their linguistic diversity nor their narrative arcs’ complexity.
The development of literary language in context
Regarding the trends towards readability alone, it is reasonable to assume that they are the effect of an overall change of the English language. Similar tendencies towards simplification have been found for fiction (Sherman, 1893; Liddle, 2019) but is not as obvious in other domains (Säily et al., 2017). Moreover, scientific and journalistic prose has even shown an opposed trend, with texts becoming more difficult to read (Plavén-Sigray et al., 2017; Danielson et al., 1992). If this trend is not an effect of language change, seeing it in literature can give way to intriguing hypotheses. The emergence of what scholars have called mass readership (Klancher, 1983) and a widening of the alphabetized population might have pushed the success of easier books, while the increasingly pressing market logic applied to the editorial world might have helped shaping literary style into simpler and simpler forms, easier to consume in a shorter time (Winter and O’Neill, 2022). It is also possible that in the last century, difficulty of reading has shifted from a virtue to a vice in the view of the English writing world, with novelists and publishers alike slowly favouring more direct or transparent prose.
Read our full study, “Readability and Complexity: Diachronic Evolution of Literary Language Across 9000 Novels”, here (pp. 235-47).
A note on the corpus
A large-scale, diachronic study is only as good as the corpus…
The Chicago Corpus was a valuable resource for our study, as it encompasses an expansive and representative sample of widely read Anglophone literature over a century, allowing for a robust analysis. Still, it is worth noting that the corpus has a geographical bias: most authors are of US origin and few are non-Anglophone. This bias inevitably situates the entire analysis within an Anglophoneliterary field. Moreover – perhaps also due to an inherent skew in this field – only 36% of authors are women. While these imbalances do not inherently undermine our experiments, it is crucial to bear them in mind when interpreting the results. Moreover, when estimating the canonicity of works in the corpus we have relied on external lists that are, to an extent, characterised by similar biases, for example the Norton Anthology, which is similar in its Anglophone and gender bias (Pope, 2019). We trust that any interpretation of our findings will have these limitations in mind.
References
Bizzoni, Yuri, Pascale Feldkamp Moreira, Nicole Dwenger, Ida Marie S. Lassen, Mads Rosendahl Thomsen & Kristoffer L. Nielbo. 2023. Good Reads and Easy Novels: Readability and Literary Quality in a Corpus of US-published Fiction. Proceedings of the 24th Nordic Conference on Computational Linguistics (NoDaLiDa), 42–51.
Danielson, Wayne A., Dominic L. Lasorsa, and Dae S. Im. 1992. Journalists and novelists: A study of diverging styles. Journalism Quarterly, 69(2):436– 446.
Degaetano-Ortlieb, Stefania and Elke Teich. 2022. Toward an optimal code for communication: The case of scientific English. Corpus Linguistics and Linguis- tic Theory, 18(1):175–207.
Klancher, Jon P.. 1983. From “crowd” to “audience”: The making of an english mass readership in the nineteenth century. ELH, 50(1):155–173.
Liddle, Dallas. 2019. Could Fiction Have an Information History? Statistical Probability and the Rise of the Novel. Journal of Cultural Analytics, page 22.
Moretti, Franco. 2000. The slaugtherhouse of literature. MLQ: Modern Language Quarterly, 61(1):207–227.
Plavén-Sigray, Pontus, Granville James Matheson, Björn Christian Schiffler, and William Hedley Thompson. 2017. Research: The readability of scientific texts is decreasing over time. eLife, 6:e27725.
Pope, Colin. 2019. We Need to Talk About the Canon: Demographics in ‘The Norton Anthology’.
Sherman, Lucius A.. 1893. Analytics of Literature: A Manual for the Objective Study of English Prose and Poetry. Athenaeum Press. Ginn.
Säily, Tanja, Arja Nurmi, Minna Palander-Collin, and Anita Auer, editors. 2017. Exploring Future Paths for Historical Sociolinguistics, volume 7 of Advances in Historical Sociolinguistics. John Benjamins Publishing Company, Amsterdam.
Underwood, Ted. 2019. Distant Horizons: Digital Evidence and Literary Change. University of Chicago Press.