In a recent conference paper, entitled “Good Reads and Easy Novels: Readability and Literary Quality in a Corpus of US-published Fiction” for the 2023 NoDaLiDa conference, we looked into classic measures of “readability” and how they relate to reader appreciation. We used The Chicago Corpus of 9,000 novels published in the US between 1880 and 2000, compiled by Hoyt Long and Richard So.
In linguistics, early studies of readability had an educational and social aim in developing formulas that could readily be applied to texts. These would enable writers and publishers to make, for example, didactic books more accessible, reduce technical jargon in documents produced for the general public, and adjust texts according to the intended audience (Dubay 2004). The result has been a series of popular and amply tested formulas, each modelling readability in slightly different ways. They vary according to what aspect of a text they take into account, but typically combine features such as sentence length, word length, and the presence of complex words. Even if we might say that how “easy” a text actually is depends very much on reader characteristics (background, situation, knowledge), it is widely accepted that simple textual features such as sentence length, syllables per word and lexical diversity do impact reading experience.
But… Can “readability” tell us anything about literary texts?
So while readability measures seem to work well for assessing, for example, at what grade level in education a non-fiction text is appropriate, it is less clear how well readability formulas work on a literary text (Nelson et al. 2012) – and whether they should work at all. In literary studies, Sherman (1893) was one of the first scholars to propose that a certain simplicity (lower average sentence-length) should be a marker of a “better” style. His argument then was that the language of literature had been evolving (and in a positive sense) to become more concise or direct: closer to the way we speak.
If we leave aside the question whether the development in literary language Sherman indicated is true or not, we might ask whether a simplification of literary language should be considered a positive development. Is concise and direct also “better”? And is that true for all “types” of literature?
It is a widespread conception that bestsellers are easy to read, and today readability formulas are popular in creative writing and publishing. For example, formulas are implemented in Microsoft Word, as in text-editing tools such as the Hemingway or Marlowe editors – which encourage writing texts that are “easier” to read in terms of the formulas.
However, on the large scale, readability does not seem to be clearly linked to reader appreciation - rather, previous studies show conflicting results. Studying a small corpus of bestsellers and more canonical works, Martin (1996) found no difference in readability score, while Garthwaite (2014) found differences between bestsellers and commercially endorsed book-list titles (like Oprah’s Book Club). Maharjan et al. (2017) note that readability is actually a weak measure for estimating popularity of books, in comparison to, for example, n-grams. Still, many studies of literary success or perceived literary quality have tried to capture some aspect of text complexity by examining texts in terms of, for example, sentence-length or vocabulary richness – features upon which formulae of readability are directly or indirectly based.
On one hand, studies have often used relatively small corpora, and because scales of readability – perhaps especially for literary texts – register only small differences when used on texts intended for adults, it may be that differences only become clear when we scale up. On the other hand, it may be that readability tells us little about how “popular” or “appreciated” a text is in the general sense. But that is also – possibly – because we are looking to find preferences in a general audience, while “the audience” in reality consists of many different audiences, with many different preferences. To examine whether some readers have a preference for “easier” novels, we compared several different “audiences”. Namely, we examined the characteristics of novels that were long-listed for very high-brow literary awards – the Pulitzer, the National Book Award and the Hugo Awards – to the characteristics of titles that get higher ratings on GoodReads and those more often found in libraries.
Interlude – applying readability formulas to literature
Since the 1920s and the success of the Flesch and Dale-Chall formulas of the 1950s, various measures of readability have been developed that have combined sentence-, word length and/or number of syllables to assess text difficulty. There were more than 200 different versions of readability formulas already in the 1980s (Dubay, 2004), and new ones continue to be introduced, as well as old ones revised. There are, however, “classic” readability formulas that are still very much in use today (Dubay 2004; Stajner et al. 2012). For the present study, we used five different “classic” formulas of readability: The Flesch Grade Level, the Flesch-Kinkaid Grade Level, the SMOG Readability Formula, the Automated Readability Index (ARI), and the New Dale-Chall Readability Formula.
In our paper, we found that these five classic formulas are very closely correlated. They seem to measure approximately the same things, having also a medium to strong correlation to the stylistic features on which they are based (sentence length) and, to an extent, with other measure that we could call measures of “difficulty”, such as lexical diversity (MSTTR) or the “compressibility” of a text in terms of how much off-the-shelf compressors like the bzip can compress the file.
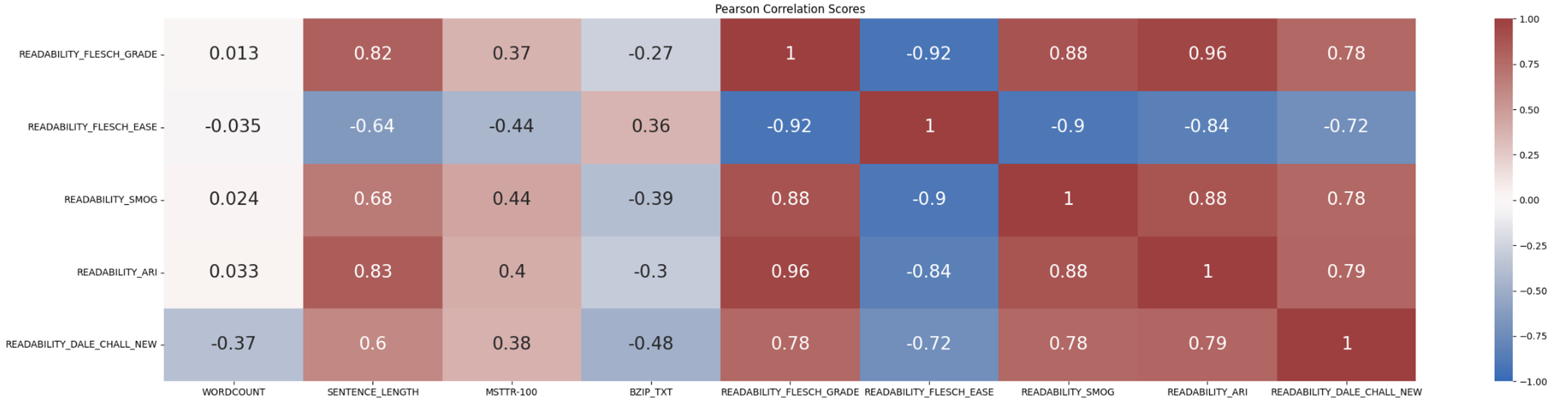
We noted that the Dale-Chall formula seems to be a little less correlated to our other readability formulas, which is possibly because it uses an external list of “easy words” against which it compares a given text, while the other measures use word length and number of syllables to measure the difficulty of the vocabulary instead, based on the assumption that “harder” words are also longer.
We did some additional experiments with two of the formulas, the Flesch Reading Ease and the Dale-Chall, to try estimating the adequacy of readability formulas for literary fiction, using some novels of selected authors from the Chicago Corpus that are generally perceived more or less “difficult”. We chose novels that critics generally agree write “difficult” novels (James Joyce, Virginia Woolf, Samuel Beckett), but also more popular authors (Stephen King, Agatha Christie) and “simpler” texts, whether this simplicity is in their case a stylistic move (Ernest Hemingway) or because they target a young audience (Beatrix Potter).
The Flesch Reading Ease measure is based on the average sentence length and average syllables per word (length): the first formula for readability, developed by Rudolf Flesch in 1943. This formulas has seen various revisions (e.g. the Flesch-Kinkaid Grade Level), but continues to be widely used today. The Flesch score is between 0 and 100, where a higher number indicates more readable texts. For example, fiction tends to have a Flesch Reading Ease above 70 and below 90, in contrast to scientific texts that often score below 30 (Flesch, 1948). James Joyce’s Ulysses, for example, has a score of 83.3 – and Stephen King’s novels land similarly between 80.6 and 91.4(The Girl Who Loved Tom Gordon is the “hardest”, Wizard And Glass is the “easiest” to read).
Another, newer, formula is the New Dale–Chall Readability Formula, a 1995 revision of the Dale-Chall readability score (Chall and Dale, 1995). It is based on the average sentence length and the percentage of ”difficult words”: words which do not appear on a list of words which 80 percent of fourth-graders would know (Dale and Chall, 1948). In terms of Dale-Chall, Ulysses scores higher, at 5.4, and King’s novels score on average 4.9. The Dale-Chall formula seems to give us a result closer to the intuition that Ulysses is harder to read than a Stephen King novel. Still, this difference between measures hints at the issues of which measure to apply.
We see in the below figure that this might have to do with readability formulas taking sentence length as an overly important factor: Ulysses has shorter sentences than Stephen King’s novels which may lead to a high Flesch Ease score – despite Ulysses having longer words and a higher type-token ratio. In terms of Dale-Chall, its low percentage of easy words in Ulysses is considered, and so the Dale-Chall is able to show a difference between Joyce and King, with Joyce less readable.
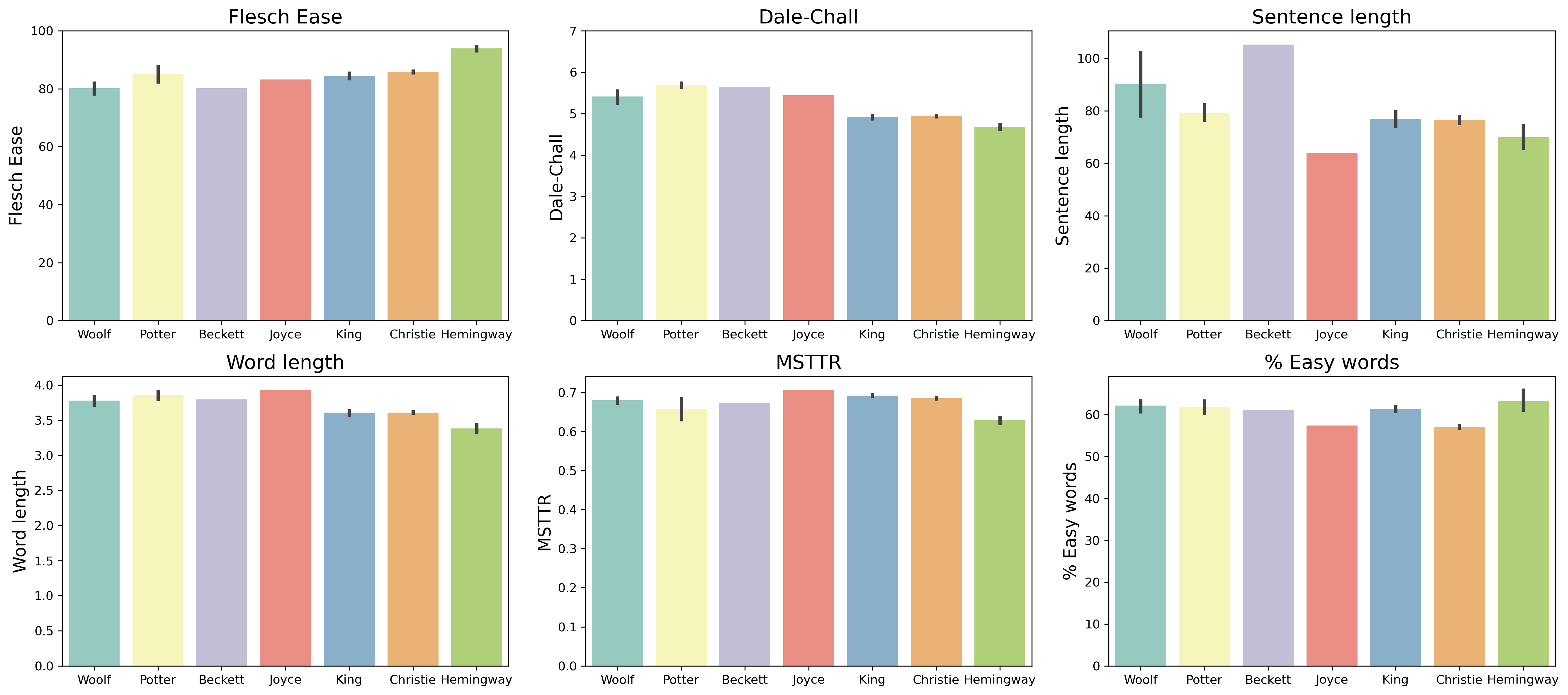
Note that the Flesch Ease and Dale-Chall formulas show reversed results: a higher Flesch Ease score means a more readable text; a higher Dale-Chall score means a less readable text. Therefore, Hemingway has the highest Flesch Ease score, but the lowest Dale-Chall score, making Hemingway the most readable author in our selection.
Take, for example, Beckett’s novel Murphy which here appears less readable than other novels (low Flesch Ease score, high Dale-Chall score). Even if it has a relatively high percentage of easy words, it has a very high sentence length and word length, which weighs heavy enough for the Dale-Chall formula to place it second to highest in our selection of novels. Conversely, Hemingway is the most “readable” author in our selection (a nice result, seeing that Hemingway is famous for his simple and unadorned style), which may have to do with a short sentence and word length, and a high percentage of easy words.
It should be noted that the scores Beatrix Potter’s novels, like The Tale of Tom Kitten, are quite puzzling. They seem more difficult to read in terms of both Flesh Ease and Dale-Chall score, even if we would intuitively suppose them to be “easy” childrens’ stories. Some of this may be due to Potter’s texts being very short, so that few data-points have the effect that the adequate readability score is not properly reflected. Moreover, Potter uses many proper names (e.g., “the Puddle-Ducks”, “Mrs. Tabitha Twitchit”), which appear as longer words and much onomatopoeia (“pit pat paddle pat!”), words which are naturally not listed in the Dale-Chall wordlist of easy words. We might therefore be careful in assuming that readability scores work well for children’s literature.
Readability under the book cover
To further assess readability measures, we looked at Joyce’s Ulysses chapter by chapter, both in terms of readability as well as lexical richness, percentage of words contained in the Dale-Chall list of easy words, average sentence- and word length. As readability formulas are to some extent based on these simple measures, we may assume that all measures should to some extent be collinear, that is, rise and fall together.
Ulysses has on average 64 characters per sentence, while King’s novels have between 69 and 103. Looking at the novel chapter by chapter, however, we see that the actual sentence length varies greatly across the book, with the whole last chapter containing no punctuation. With a readability score off the charts, the last chapter of Ulysses, Molly’s inner dialogue, seems unreadable. Scholars may beg to differ. In fact, the last chapter is rarely considered the “hardest part” of Ulysses. Moreover, it is important to remember that although the chapter contains to actual punctuation, it still has paragraph breaks (though few) that serve a similar function.
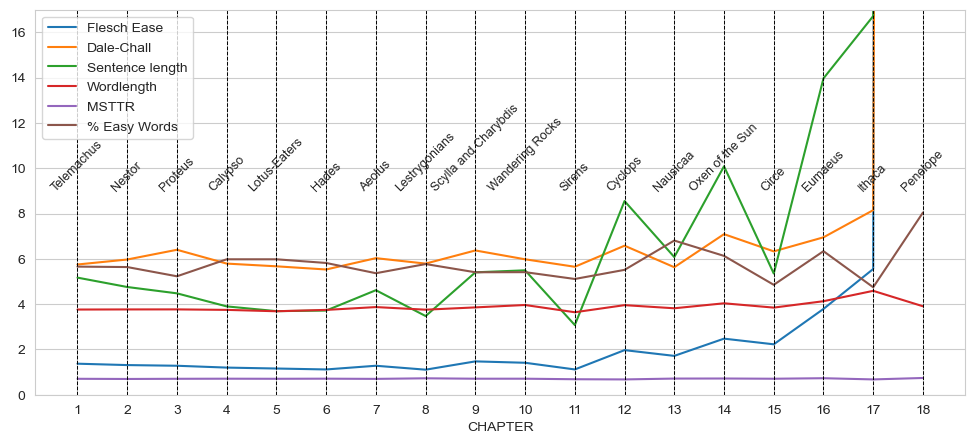
We inverted the Dale-Chall measure here to better see if the formulas rise and fall together. As such, if either Flesch Ease or Dale-Chall go up, it means a less readable prose. We further scaled down some measures, Flesch Ease, sentence length, % of easy words (multiplying by 0.1), so that the timelines landed in roughly the same interval to better see how they interact. Numbers on the x-axis show the chapter number.
Actually, we see the percentage of easy words go up, and the average word length go down in the last chapter. As such, readability measures may overestimate the importance of sentence length and therefore not adequately capture difficulty of more experimental works that depart from punctuation usage of “natural” language. But then does most fiction not use punctuation in a far more creative way than non-fiction texts? On the other hand, sentence length does seem an adequate indicator of difficulty to an extent. Take, for example, the “Ithaca” chapter, which in Ulysses has a high average sentence length, and a low percentage of easy words. The “Ithaca” chapter is known for its inventories such as:
DEBIT 1 Pork Kidney 1 Copy Freeman’s Journal 1 Bath And Gratification Tramfare 1 In Memoriam Patrick Dignam 2 Banbury cakes 1 Lunch 1 Renewal fee for book 1 Packet Notepaper and Envelopes 1 Dinner and Gratification 1 Postal Order and Stamp Tramfare 1 Pig’s Foot 1 Sheep’s Trotter 1 Cake Fry’s Plain Chocolate 1 Square Soda Bread 1 Coffee and Bun Loan (Stephen Dedalus) refunded BALANCE
Such paragraphs inevitably affect both the difficulty of the vocabulary and average sentence length of the chapter (what are “Banbury cakes”?). As such, readability formulas are not terrible at estimating the “difficulty” of the prose in each chapter, but there are clear issues. Plotting Ulysses chapter by chapter, we also see that the general (per book) score of readability is perhaps not so representative as the internal variation within books may be very high, although Ulysses, of which each chapter is said to have a different “style”, may be an extreme case.
“Better” reads? Perspectivizing the issue
Using one readability score per book, our paper showed that more or less readability can indicate reader appreciation – but that the question is complex. There is not one general preference across audiences. Rather, different audiences seem to prefer different types of prose. For example, when looking at library holdings numbers and the GoodReads number of ratings, which may be considered a measure of how popular or “famous” a book is in the GoodReads community, we found that more readable books tend to have more ratings and tend to be held by more libraries.
However, the average GoodReads ratings of books (how many “stars” it has) appeared to have no link with the readability of books. Conversely, longlisted titles have an inverse relation with readability: books with slightly more difficult prose on the readability metrics’ scale are more probable to be long-listed for awards. In conclusion, we found that this difference in preferences between what books are held in libraries and rated more often, and those that are longlisted for awards might indicate a divide between (less readable) high-brow and (more readable) ”popular” literature, but the fact that there is no link with GoodReads average rating may point to a slightly more nuanced conclusion.
In other words, surface-level simplicity improves a text’s likeability only if we equate it with popularity or fame: its circulation in libraries and its popularity on Goodreads. However, the correlations of average number of ratings and library holdings with readability measures do not appear linear or monotonic, meaning that there might also be a ”point of balance” between too easy and too difficult.
An important finding was also the difference in preference for more or less readable texts between crowd-based (libraries, GoodReads) and expert-based (literary awards) proxies of “reader appreciation” or “literary quality”. It indicates that the criteria change across audiences – that ”literary quality” cannot be quantified reliably if it is reduced to a single golden standard. Future studies might further try to perspectivize the issue, using more proxies of quality as well as more sophisticated stylometric measures to see whether interactions can provide a clearer picture of what we perceive as literary quality – and how we can measure “readability” or “difficulty” of literary texts.
Our paper on readability and proxies of reader appreciation was presented at the 2023 NoDaLiDa and is available in the proceedings.
References:
Dubay, William. 2004. The Principles of Readability. Impact Information. Garthwaite, Craig L. 2014. “Demand Spillovers, Combative Advertising, and Celebrity Endorsements.” American Economic Journal: Applied Economics 6 (2): 76–104. https://doi.org/10.1257/app.6.2.76.
Maharjan, Suraj, John Arevalo, Manuel Montes, Fabio A. González, and Thamar Solorio. 2017. “A Multi-Task Approach to Predict Likability of Books.” In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 1, Long Papers, 1217–27. Valencia, Spain: Association for Computational Linguistics. https://aclanthology.org/E17-1114.
Martin, Claude. 1996. “Production, Content, and Uses of Bestselling Books in Quebec.” Canadian Journal of Communication 21 (4): cjc.1996v21n4a958. https://doi.org/10.22230/cjc.1996v21n4a958.
Nelson, Jessica, Charles Perfetti, David Liben, and Meredith Liben. 2012. “Measures of Text Difficulty: Testing Their Predictive Value for Grade Levels and Student Performance.” Report submitted to the Gates Foundation.
Sherman, Lucius Adelno. 1893. Analytics of Literature: A Manual for the Objective Study of English Prose and Poetry. Ginn.
Stajner, Sanja, Richard Evans, Constantin Orasan, and Ruslan Mitkov. 2012. “What Can Readability Measures Really Tell Us About Text Complexity?” In Proceedings of Workshop on Natural Language Processing for Improving Textual Accessibility, 14–22. Istanbul, Turkey: Association for Computational Linguistics. http://nlx-server.di.fc.ul.pt/~sanja/StajnerEtAl-12.pdf.