State of the Art Comparison#
In the paper DaCy: A Unified Framework for Danish NLP we compare DaCy’s models with other Danish language processing pipelines. This page represents only parts of the paper. For a more comprehensive evaluation we recommend reading the paper.
The table below shows the performance of Danish language processing pipelines scored on the DaNE test set, including part-of-speech tagging (POS), named entity recognition (NER) and dependency parsing. The best scores in each category are highlighted with bold and the second best is underlined. Empty cells indicate that the framework does not include the specific model.
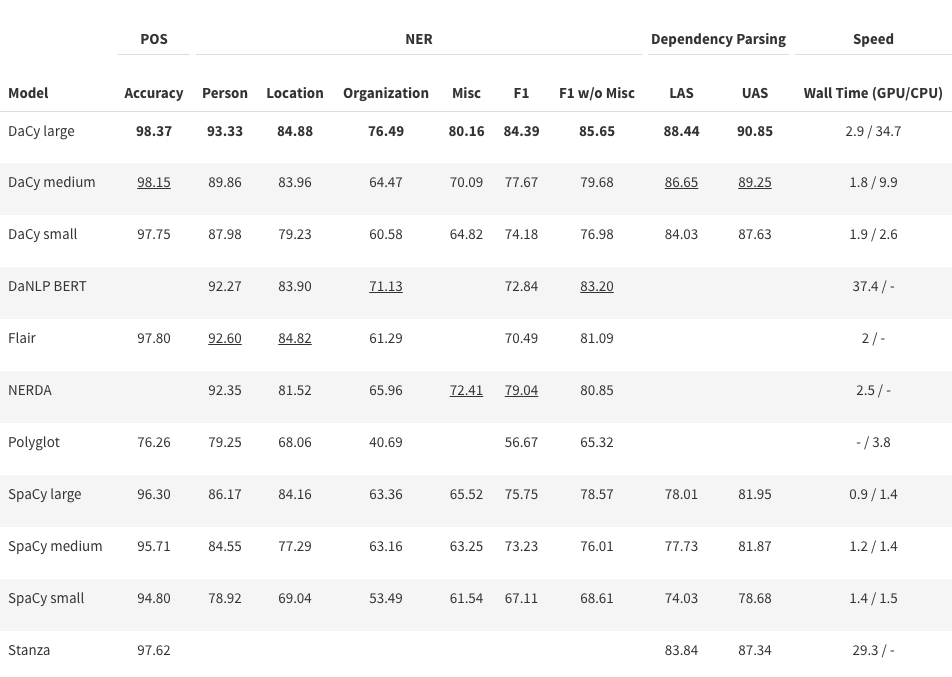
Stanza uses the spacy-stanza implementation. The speed of the DaNLP model is as reported by the framework (v. 0.0.11), which does not utilize batch input. However, given the model size, it can be expected to reach speeds comparable to DaCy medium.
Want to see more performance metrics for Named entity recognition?
If you want to see a updated comparison of the performance of the NER models, check out the NER performance page.
What is LAS and UAS?
Unlabelled attachment score (UAS) denotes the percentage of words that get assigned the correct head, while labelled attachment score (LAS) is the percentage of words that get assigned the correct head and label. For more information, read the following chapter by Jurafsky and Martin.
From the table we see that DaCy large obtains state-of-the-art on all tasks, most notably on NER and dependency parsing. DaCy medium is a good alternative especially when running on CPU, where SpaCy large might also be considered. If you are only interested in NER, and POS, Flair is also a viable option for CPU usage.
Measuring Performance
Typically when measuring performance on these benchmark there is a tendency to feed the model the gold standard tokens. While this allows for easier comparisons of modules and architectures, it inflates the performance metrics. Further, it does not proberly reflect what you are really interested in: the performance you can expect when you apply the model. Therefore, we measure the performance using the models own tokenizer or SpaCy’s tokenizer if it performs better. Polyglot and Stanza performed better with their own tokenizers while the remaining models performed best with SpaCy’s.
State-of-the-Art#
While the above tables are convenient and give and quick overview over the natural language processing landscape for Danish NLP it isn’t continually updated. Thus the following three badges denotes the current ranking of DaCy.
![]()
![]()
![]()
Note
Note that striving for state-of-the-art performance isn’t always ideal often inference speed, model robustness and model biases is important too. DaCy strive to strike a balance between these categories when selecting its candidate models. For more information on this check out the section on model robustness and biases.