Dirichlet Multinomial Mixture Model#
The tweetopic.DMM class provides utilities for fitting and using Dirichlet Multinomial Mixture Models.
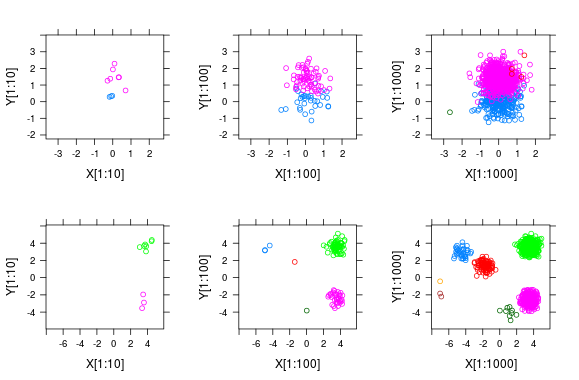
Simulation of 1000 observations drawn from a DMM source: Wikipedia
{kind=link}
The Dirichlet Multinomial Mixture Model or DMM is a generative probabilistic model, that assumes that all data points in the population are generated from a mixture of dirichlet distributions with unknown parameters.
DMMs can be thought of as a fuzzy clustering method, but can also be employed as topic models. It has been demonstrated that DMMs work particularly well for topic modelling over short texts (Yin and Wang, 2014).
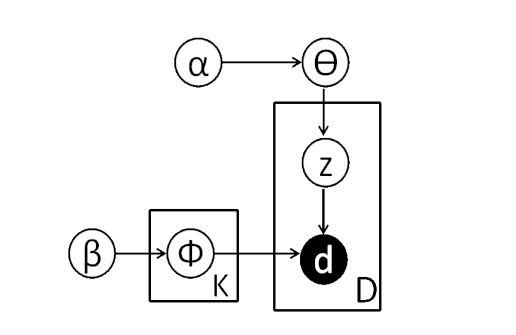
Graphical model of DMM with plate notation (Yin & Wang, 2014)
Dirichlet Multinomial Mixtures in tweetopic are fitted with Gibbs sampling . Since Gibbs sampling is an iterative ḾCMC method, increasing the number of iterations will usually result in better convergence.
Rule 1: Prefer tables with more students.
Rule 2: Choose a table where students have similar preferences to your own.
Usage#
Creating a model:
from tweetopic import DMM
dmm = DMM(
n_components=15,
n_iterations=200,
alpha=0.1,
beta=0.2,
)
Fitting the model on a document-term matrix:
dmm.fit(doc_term_matrix)
Predicting cluster labels for unseen documents:
dmm.transform(new_docs)
References#
Yin, J., & Wang, J. (2014). A Dirichlet Multinomial Mixture Model-Based Approach for Short Text Clustering. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (pp. 233–242). Association for Computing Machinery.