Models
Stormtrooper supports a wide variety of model types for zero and few-shot classification. This page includes a general overview of how the different methods approach this task.
Text Generation
LLMs are a relatively easy to utilise for zero and few-shot classification, as they contain a lot of general language-based knowledge and can provide free-form answers. Models that generate text typically have to be prompted. One has to pass free-form text instructions to a model, to which it can respond with a (hopefully) appropriate answer.
Instruction Models
Models used in chatbots and alike are typically instruction-finetuned generatively pretrained transformer models. These models take a string of messages and generate a new message at the end by predicting next-token probabilities.
These models also typically take a system prompt a base prompt that tells the model what persona it should have and how it should behave when presented with instructions.
You can use instruction models from both HuggingFace Hub, but also OpenAI in stromtrooper.
from stormtrooper import Trooper
# Model from HuggingFace:
model = Trooper("HuggingFaceH4/zephyr-7b-beta")
# OpenAI model
model = Trooper("gpt-4")
stormtrooper.openai.OpenAIClassifier
Bases: ChatClassifier
Use OpenAI's models for zero and few-shot text classification.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
model_name |
str
|
Name of the OpenAI chat model to use. |
'gpt-3.5-turbo'
|
temperature |
float
|
Temperature for text generation. Higher temperature results in more diverse answers. |
1.0
|
prompt |
str
|
Prompt template to use for each text. |
default_prompt
|
system_prompt |
str
|
System prompt for the model. |
default_system_prompt
|
max_new_tokens |
int
|
Maximum number of new tokens to generate. |
256
|
fuzzy_match |
bool
|
Indicates whether responses should be fuzzy-matched to closest learned label. |
True
|
progress_bar |
bool
|
Inidicates whether a progress bar should be desplayed when obtaining results. |
True
|
Source code in stormtrooper/openai.py
14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 | |
predict(X)
Predicts most probable class label for given texts.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
X |
Iterable[str]
|
Texts to label. |
required |
Returns:
| Type | Description |
|---|---|
array of shape (n_texts)
|
Array of string class labels. |
Source code in stormtrooper/openai.py
91 92 93 94 95 96 97 98 99 100 101 102 103 104 | |
stormtrooper.generative.GenerativeClassifier
Bases: ChatClassifier
Scikit-learn compatible zero shot classification with generative language models.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
model_name |
str
|
Generative instruct model from HuggingFace. |
'HuggingFaceH4/zephyr-7b-beta'
|
prompt |
str
|
You can specify the prompt which will be used to prompt the model. Use placeholders to indicate where the class labels and the data should be placed in the prompt. |
default_prompt
|
system_prompt |
str
|
System prompt for the model. |
default_system_prompt
|
max_new_tokens |
int
|
Maximum number of tokens the model should generate. |
256
|
fuzzy_match |
bool
|
Indicates whether the output lables should be fuzzy matched to the learnt class labels. This is useful when the model isn't giving specific enough answers. |
True
|
progress_bar |
bool
|
Indicates whether a progress bar should be shown. |
True
|
device |
Optional[str]
|
Indicates which device should be used for classification. Models are by default run on CPU. |
None
|
device_map |
Optional[str]
|
Device map argument for very large models. |
None
|
Attributes:
| Name | Type | Description |
|---|---|---|
classes_ |
array of str
|
Class names learned from the labels. |
Source code in stormtrooper/generative.py
14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 | |
Text2Text Models
Text2Text models not only generate text, but are trained to predict a sequence of text based on a sequence of incoming text. Input text gets encoded into a low-dimensional latent space, and then this latent representation is used to generate an appropriate response, similar to an AutoEncoder.
Text2Text models are typically smaller and faster than fully generative models, but also less performant.
from stormtrooper import Trooper
model = Trooper("google/flan-t5-small")
stormtrooper.text2text.Text2TextClassifier
Bases: ChatClassifier
Zero and few-shot classification with text2text language models.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
model_name |
str
|
Text2text model from HuggingFace. |
'google/flan-t5-base'
|
prompt |
str
|
You can specify the prompt which will be used to prompt the model. Use placeholders to indicate where the class labels and the data should be placed in the prompt. |
default_prompt
|
max_new_tokens |
int
|
Maximum number of tokens the model should generate. |
256
|
fuzzy_match |
bool
|
Indicates whether the output lables should be fuzzy matched to the learnt class labels. This is useful when the model isn't giving specific enough answers. |
True
|
progress_bar |
bool
|
Indicates whether a progress bar should be shown. |
True
|
device |
Optional[str]
|
Indicates which device should be used for classification. Models are by default run on CPU. |
None
|
device_map |
Optional[str]
|
Device map argument for very large models. |
None
|
Attributes:
| Name | Type | Description |
|---|---|---|
classes_ |
array of str
|
Class names learned from the labels. |
Source code in stormtrooper/text2text.py
12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 | |
Sentence Transformers + SetFit
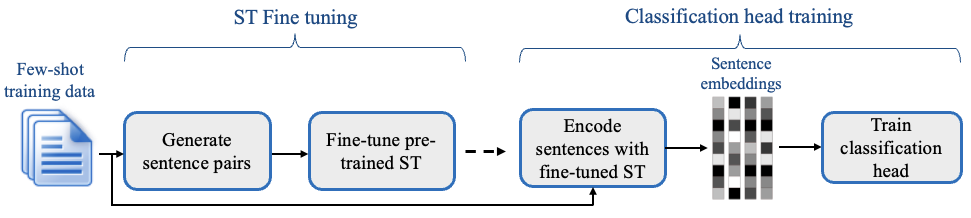
SetFit is a commonly employed trick for training classifiers on a low number of labelled datapoints. It involves:
- Finetuning a sentence encoder model using contrastive loss, where positive pairs are the examples that belong in the same category, and negative pairs are documents belonging to different classes.
- Training a classification head on the finetuned embeddings.
When you load any encoder-style model in Stormtrooper, they are automatically converted into a SetFit model.
from stormtrooper import Trooper
model = Trooper("all-MiniLM-L6-v2")
stormtrooper.set_fit.SetFitClassifier
Bases: BaseEstimator, ClassifierMixin
Zero and few-shot classifier using the SetFit technique with encoder models.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
model_name |
str
|
Name of the encoder model. |
'sentence-transformers/all-MiniLM-L6-v2'
|
device |
str
|
Device to train and run the model on. |
'cpu'
|
classification_head |
Optional[ClassifierMixin]
|
Classifier to use as the last step. Defaults to Logistic Regression when not specified. |
None
|
n_epochs |
int
|
Number of trainig epochs. |
10
|
batch_size |
int
|
Batch size to use during training. |
32
|
sample_size |
int
|
Number of training samples to generate (only zero-shot) |
8
|
template_sentence |
str
|
Template sentence for synthetic samples (only zero-shot) |
'This sentence is {label}.'
|
random_state |
int
|
Seed to use for stochastic training. |
42
|
Source code in stormtrooper/set_fit.py
11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 | |
Natural Language Inference
Natural language inference entails classifying pairs of texts based on whether they are congruent with each other. Models finetuned for NLI can also be utilised for zero-shot classification.
from stormtrooper import Trooper
model = Trooper("facebook/bart-large-mnli").fit(None, ["dog", "cat"])
model.predict_proba(["He was barking like hell"])
# array([[0.95, 0.005]])
stormtrooper.zero_shot.ZeroShotClassifier
Bases: BaseEstimator, TransformerMixin, ClassifierMixin
Scikit-learn compatible zero shot classification with HuggingFace Transformers.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
model_name |
str
|
Zero-shot model to load from HuggingFace. |
'facebook/bart-large-mnli'
|
progress_bar |
bool
|
Indicates whether a progress bar should be shown. |
True
|
device |
str
|
Indicates which device should be used for classification. Models are by default run on CPU. |
'cpu'
|
Attributes:
| Name | Type | Description |
|---|---|---|
classes_ |
array of str
|
Class names learned from the labels. |
Source code in stormtrooper/zero_shot.py
13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 | |
fit(X, y)
Learns class labels.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
X |
Ignored |
required | |
y |
Iterable[str]
|
Iterable of class labels. Should at least contain a representative sample of potential labels. |
required |
Returns:
| Type | Description |
|---|---|
self
|
Fitted model. |
Source code in stormtrooper/zero_shot.py
45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 | |
partial_fit(X, y)
Learns class labels. Can learn new labels if new are encountered in the data.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
X |
Ignored |
required | |
y |
Iterable[str]
|
Iterable of class labels. |
required |
Returns:
| Type | Description |
|---|---|
self
|
Fitted model. |
Source code in stormtrooper/zero_shot.py
66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 | |
predict(X)
Predicts most probable class label for given texts.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
X |
Iterable[str]
|
Texts to label. |
required |
Returns:
| Type | Description |
|---|---|
array of shape (n_texts)
|
Array of string class labels. |
Source code in stormtrooper/zero_shot.py
141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 | |
predict_proba(X)
Predicts class probabilities for given texts.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
X |
Iterable[str]
|
Texts to predict probabilities for. |
required |
Returns:
| Type | Description |
|---|---|
array of shape (n_texts, n_classes)
|
Class probabilities for each text. |
Source code in stormtrooper/zero_shot.py
91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 | |
set_output(transform=None)
Set output of the transform() function to be a dataframe instead of a matrix if you pass transform='pandas'. Otherwise it will disable pandas output.
Source code in stormtrooper/zero_shot.py
173 174 175 176 177 178 179 180 181 | |
transform(X)
Predicts class probabilities for given texts.
Parameters:
| Name | Type | Description | Default |
|---|---|---|---|
X |
Iterable[str]
|
Texts to predict probabilities for. |
required |
Returns:
| Type | Description |
|---|---|
array of shape (n_texts, n_classes)
|
Class probabilities for each text. |
Source code in stormtrooper/zero_shot.py
120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 | |